
NYU and Facebook team up to supercharge MRI scans with AI
Magnetic resonance imaging is an invaluable tool in the medical field, but it’s also a slow and cumbersome process. It may take an fifteen minutes or an hour to complete a scan, during which time the patient, perhaps a child or someone in serious pain, must sit perfectly still. NYU has been working on a way to accelerate this process, and is now collaborating with Facebook with the goal of cutting down MRI durations by 90 percent by applying AI-based imaging tools.
It’s important at the outset to distinguish this effort from other common uses of AI in the medical imaging field. An X-ray, or indeed an MRI scan, once completed, could be inspected by an object recognition system watching for abnormalities, saving time for doctors and maybe even catching something they might have missed. This project isn’t about analyzing imagery that’s already been created, but rather expediting its creation in the first place.
The reason MRIs take so long is because the machine must create a series of 2D images or slices, many of which must be stacked up to make a 3D image. Sometimes only a handful are needed, but for full fidelity and depth — for something like a scan for a brain tumor — lots of slices are required.
The FastMRI project, begun in 2015 by NYU researchers, investigates the possibility of creating imagery of a similar quality to a traditional scan, but by collecting only a fraction of the data normally needed.
Think of it like scanning an ordinary photo. You could scan the whole thing… but if you only scanned every other line (this is called “undersampling”) and then intelligently filled in the missing pixels, it would take half as long. And machine learning systems are getting quite good at tasks like that. Our own brains do it all the time: you have blind spots with stuff in them right now that you don’t notice because your vision system is filling in the gaps — intelligently.

The data collected at left could be ‘undersampled’ as at right, with the missing data filled in later.
If an AI system could be trained to fill in the gaps from MRI scans where only the most critical data is collected, the actual time during which a patient would have to sit in the imaging tube could be reduced considerably. It’s easier on the patient, and one machine could handle far more people than it does doing a full scan every time, making scans cheaper and more easily obtainable.
The NYU School of Medicine researchers began work on this three years ago and published some early results showing that the approach was at least feasible. But like an MRI scan, this kind of work takes time.
“We and other institutions have taken some baby steps in using AI for this type of problem,” explained NYU’s Dan Sodickson, director of the Center of Advanced Imaging Innovation and Research there. “The sense is that already in the first attempts, with relatively simple methods, we can do better than other current acceleration techniques — get better image quality and maybe accelerate further by some percentage, but not by large multiples yet.”
So to give the project a boost, Sodickson and the radiologists at NYU are combining forces with the AI wonks at Facebook and its Artificial Intelligence Research group (FAIR).
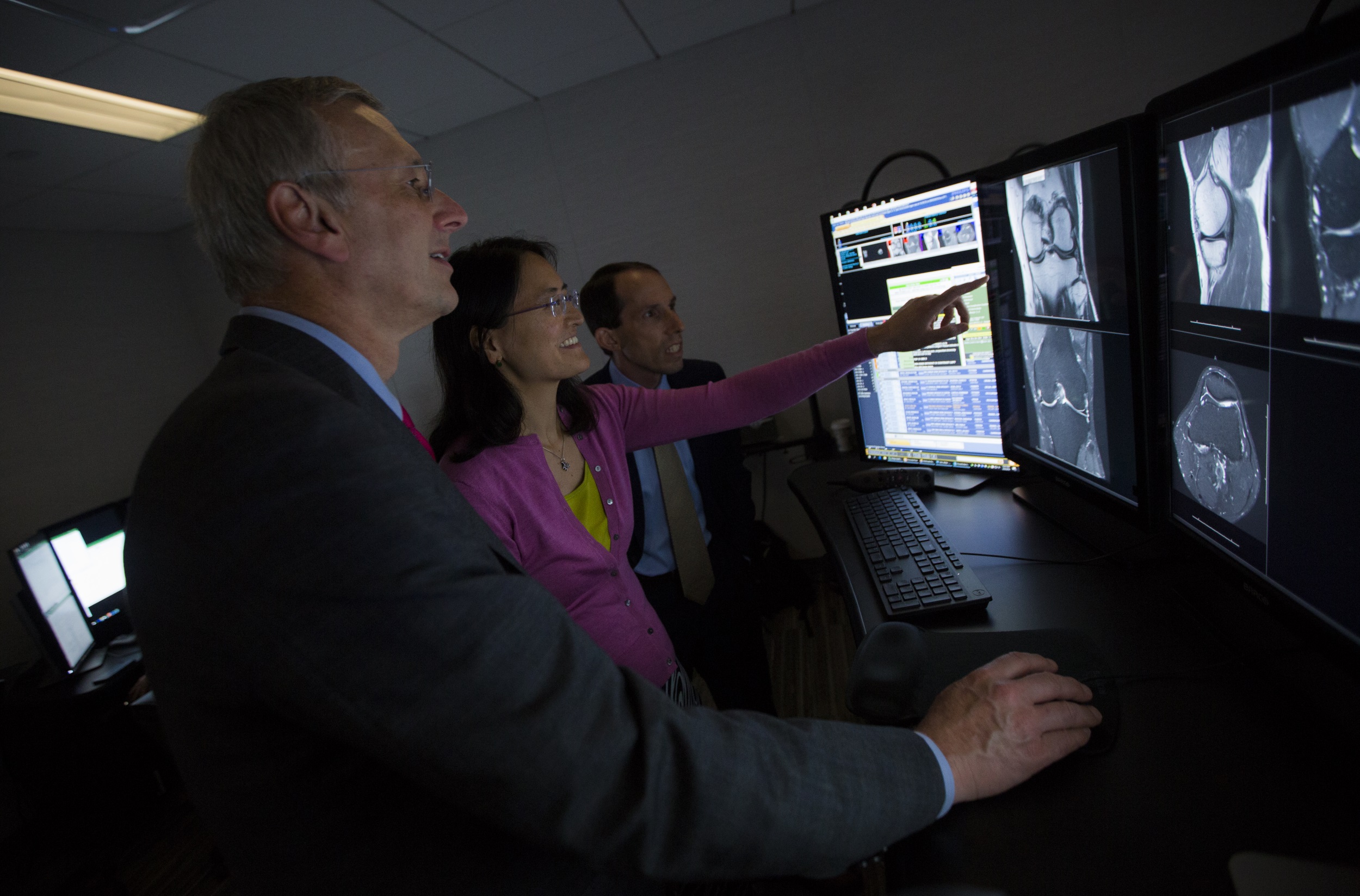
NYU School of Medicine’s Department of Radiology chair Michael Recht, MD, Daniel Sodickson, MD, vice chair for research and director of the Center for Advanced Imaging Innovation and Yvonne Lui, MD, director of artificial intelligence, examine an MRI.
“We have some great physicists here and even some hot stuff mathematicians, but Facebook and FAIR have some of the leading AI scientists in the world. So it’s complimentary expertise,” Sodickson said.
And while Facebook isn’t planning on starting a medical imaging arm, FAIR has a pretty broad mandate.
“We’re looking for impactful but also scientifically interesting problems,” said FAIR’s Larry Zitnick. AI-based creation or re-creation of realistic imagery (often called “hallucination”) is a major area of research, but this would be a unique application of it — not to mention one that could help some people.
With a patient’s MRI data, he explained, the generated imagery “doesn’t need to be just plausible, but it needs to retain the same flaws.” So the computer vision agent that fills in the gaps needs to be able to recognize more than just overall patterns and structure, and to be able to retain and even intelligently extend abnormalities within the image. To not do so would be a massive modification of the original data.
Fortunately it turns out that MRI machines are pretty flexible when it comes to how they produce images. If you would normally take scans from 200 different positions, for instance, it’s not hard to tell the machine to do half that, but with a higher density in one area or another. Other imagers like CT and PET scanners aren’t so docile.
Even after a couple years of work the research is still at an early stage. These things can’t be rushed, after all, and with medical data there ethical considerations and a difficulty in procuring enough data. But the NYU researchers’ ground work has paid off with initial results and a powerful dataset.
Zitnick noted that because AI agents require lots of data to train up to effective levels, it’s a major change going from a set of, say, 500 MRI scans to a set of 10,000. With the former dataset you might be able to do a proof of concept, but with the latter you can make something accurate enough to actually use.
The partnership announced today is between NYU and Facebook, but both hope that others will join up.
“We’re working on this out in the open. We’re going to be open sourcing it all,” said Zitnick. One might expect no less of academic research, but of course a great deal of AI work in particular goes on behind closed doors these days.
So the first steps as a joint venture will be to define the problem, document the dataset and release it, create baselines and metrics by which to measure their success, and so on. Meanwhile the two organizations will be meeting and swapping data regularly and running results past actual clinicians.
“We don’t know how to solve this problem,” Zitnick said. “We don’t know if we’ll succeed or not. But that’s kind of the fun of it.”
from TechCrunch https://ift.tt/2LbEYKe



No comments